

温馨提示:在 ChatGPT 官网(www.chatgpt.com)使用 GPT-5.5、ChatGPT-Image-2 等模型时,需要 ChatGPT Plus 或更高等级的会员权限。如需购买帐号或代充值会员,请扫码添加我们客服咨询。

昨天OpenAI推出的文生成视频大模型Sora可谓是在科技媒体头条一时风头无两,大放异彩。其惊人的逼真细节、流畅的视频动作,以及准确的文本语义还原令人惊叹。许多媒体、科技专家和电影导演纷纷指出,Sora的亮相不仅使一直在该领域深耕的Pika、Stability等知名企业相形见绌,甚至可能对整个影视行业产生颠覆性影响。
Sora主要令人惊艳的点在于可以生成60s的高清视频,一镜到底,并且多个场景镜头无缝衔接,视频主体不变,各个物体间的物理位置关系不变。
今天OpenAI发布了Sora的技术报告,我们来仔细研读一下Sora的技术原理~ (Sora官方技术报告链接:https://openai.com/research/video-generation-models-as-world-simulators)

报告总览
首先我们来梳理一下Sora报告的技术要点:
模型训练
1、Sora的架构是扩散模型Diffusion Model和Transformer.
在最开始的文生视频领域,常用的有RNN\GAN\DM模型。Sora属于扩散模型。
扩散模型展现出卓越的优势,相较于GAN而言,它在生成多样性和训练稳定性方面更为出色。最为关键的是,在图片和视频生成领域,扩散模型呈现出更为广阔的发展空间。相较于GAN模型本质上是机器对人的模仿,扩散模型更像是机器真正学会了“成为一个人”。这不仅突显了其在生成领域的前沿地位,还彰显了其在理解和模拟人类特质方面的独特能力。因此,扩散模型不仅在技术上取得了显著的进步,更为全面地超越了传统的生成对抗网络。
说得直白一点,GAN模型就像是一位学徒,他一边不停地对着样本作画,一边接受着老师的不断评分以进行提升“训练”(生成器和判别器的相互博弈)。最终画家可能取得了不小的进步画出逼真的作品,但整个过程难以精确控制,有时候会走火入魔,输出一些难以理解的内容。而且,他的进步主要是在不断地模仿先前的作品,缺乏创造性。
相比之下,扩散模型则更像是一位勤奋且聪明的创作者。他不仅仅是机械地仿作,而是在学习大量作品的同时,深刻理解图像内涵及图像之间的关系。他具备对图像进行独立创作思考的能力。不同于GAN的局限性,扩散模型在创造性方面表现更出色,为未来的发展提供了更广阔的可能性。
我们来看看23年和今年不同文生视频的对比图:

2、Sora模型在训练时是先用预训练模型把各种不同的视频源文件编码统一都转化为Patch表示,接着把时空要素作为Transformer的token进行训练。
大型语言模型之所以在之前取得成功,关键在于Token的出色应用。Token这一概念,可被视作一种巧妙的工具,它成功地将代码、数学以及各种自然语言有机地统一在一起,为进行大规模训练提供了高效而便捷的手段。这种统一不仅简化了模型的训练过程,还促使了不同领域知识的有效交融,为模型的全面学习提供了有力支持。
在视频模型Sora的训练中,OpenAI巧妙地将Token的思想延伸,并引入了“Patch”概念。这里,“Patch”可以被译为图块,这一概念的引入进一步加强了对视频信息的处理能力。通过将Token理解为词元,我们可以将“Patch”视为对图像信息进行分块处理的有效手段,为Sora在处理视频生成时提供了更灵活和精准的工具。
需要强调的是,在大型语言模型的成功背后,Token并非孤立存在。其背后还有Transformer架构的协同作用,这个架构为模型提供了更为智能和高效的学习方式。Transformer架构与Token相辅相成,相互配合,使得模型在各个层面都能更好地理解和处理复杂信息。
因此,Sora作为一种视频生成扩散模型,与主流采用U-Net架构的视频生成扩散模型不同,选择采用了Transformer架构。这种创新设计不仅使Sora在视频生成领域具备独特的优势,还为模型在理解和处理更丰富、更复杂信息方面开辟了新的可能性。这样的前瞻性设计使得Sora在实际应用中表现抢眼,并为视频生成技术的进一步发展贡献了重要的经验和启示。

特点
1、自然语言的理解能力大大增强,可以贴切的理解prompt提示词。
2、可以将视频内容主体的特征保持不变。
3、可以生成长达60s的高清一镜到底视频(之前所有的文生视频大模型几乎都只能生成10s以内的视频内容)。
4、可以实现视频补全、视频延伸等等。
5、已经对真实的物理世界有了认知,可以自然理解一些简单的物理世界原理并做出视频。
Sora报告
(1) 将视觉数据转化为补丁
借鉴于大型语言模型的成功经验,这些模型通过海量的互联网数据训练,具备出色的通用能力。LLM范式的成功得益于其巧妙运用标记,这些标记巧妙地统一了文本、代码、数学以及各种自然语言模式。在研究中OpenAI思考了视觉数据生成模型如何能够继承并运用这些优势。相较于LLM拥有文本标记,Sora则通过引入视觉补丁实现其目标。过去的研究已经证明,补丁在表示视觉数据模型时是一种有效的方式。发现表明,补丁是一种高度可扩展和有效的表示方式,适用于在不同类型的视频和图像上进行生成模型的训练。在更高层面上,首先将视频压缩至较低维的潜在空间,然后通过将表示分解为时空补丁的方式,成功地将视频转换为补丁形式。这一方法为训练生成模型提供了更灵活、更有效的手段。
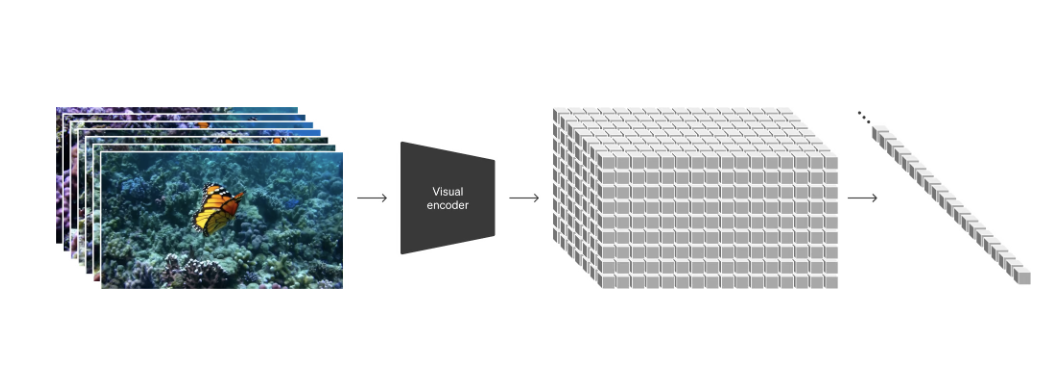
(2) 视频压缩网络
通过训练网络成功实现了对视觉数据维度的降低。这个网络以原始视频为输入,输出在时间和空间上经过压缩的潜在表示。Sora在这一压缩的潜在空间中接受训练,进而生成出新的视频。为了完善这一过程进行了解码器模型的训练,它能够将生成的潜在表示映射回像素空间,为最终的视觉输出提供了高质量的还原。
这个创新性的方法不仅能够在降低数据维度的同时保持信息的关键性,还为视觉数据处理领域带来了更为高效和灵活的解决方案。

(3) 时空潜补丁
这个“潜”,可以理解成“降维”或者“压缩”,意在用更少的信息去表达信息的本质。
给定一个压缩的输入视频,提取一系列时空补丁,充当变压器令牌。该方案也适用于图像,因为图像只是具有单帧的视频。基于补丁的表示使 Sora 能够对不同分辨率、持续时间和长宽比的视频和图像进行训练。在推理时可以通过在适当大小的网格中排列随机初始化的补丁来控制生成视频的大小。
(4) 改进的框架和构图
基于原始视频的长宽比进行训练有助于改善构图和取景效果。特别将Sora与一种常见的训练生成模型方式进行比较,即将所有训练视频裁剪为正方形的模型版本。在方形裁剪的模型训练中,有时会产生仅显示部分主体的视频的情况。相比之下,Sora模型的视频在取景效果上表现更佳,通过保留原始长宽比,成功改进了视频的构图,使其更加完整和有吸引力。
(5) 语言理解
为了训练文本到视频生成系统采用具备相应文本字幕的大量视频。引入了DALL·E 3中的重新字幕技术,首先培训了一个高度描述性的字幕生成器模型,并将其用于为训练集中的所有视频生成文本字幕。这一过程的关键是通过对高度描述性视频字幕的训练,提高文本的保真度,从而提升整体视频质量。
与DALL·E 3相似,巧妙地利用GPT将短小的用户提示转换为更为详细的字幕,然后将其发送到视频模型。这一策略使得Sora能够生成高质量视频,准确地符合用户的提示,为用户提供了更加个性化和令人满意的视觉体验。

(6) 通过图像和视频进行提示
Sora 也可以通过其他输入进行提示,例如预先存在的图像或视频。此功能使 Sora 能够执行各种图像和视频编辑任务 - 创建完美的循环视频、动画静态图像、及时向前或向后扩展视频等。

温馨提示:在 ChatGPT 官网(www.chatgpt.com)使用 GPT-5.5、ChatGPT-Image-2 等模型时,需要 ChatGPT Plus 或更高等级的会员权限。如需购买帐号或代充值会员,请扫码添加我们客服咨询。




